Multi Tier
A multi-tier caching system can be very useful when you want to boost even more the performance of you caching strategy.
To do that, we generally use a in-memory cache as the first level cache, and a distributed cache as the second level cache. In-memory cache is really fast, but it is limited by the amount of memory available on your server. Distributed cache is slower, but can store a lot more data, and is shared between your different instances.
So by using a multi-tier cache, you can have the best of both worlds. Here is a simplified diagram of the flow :
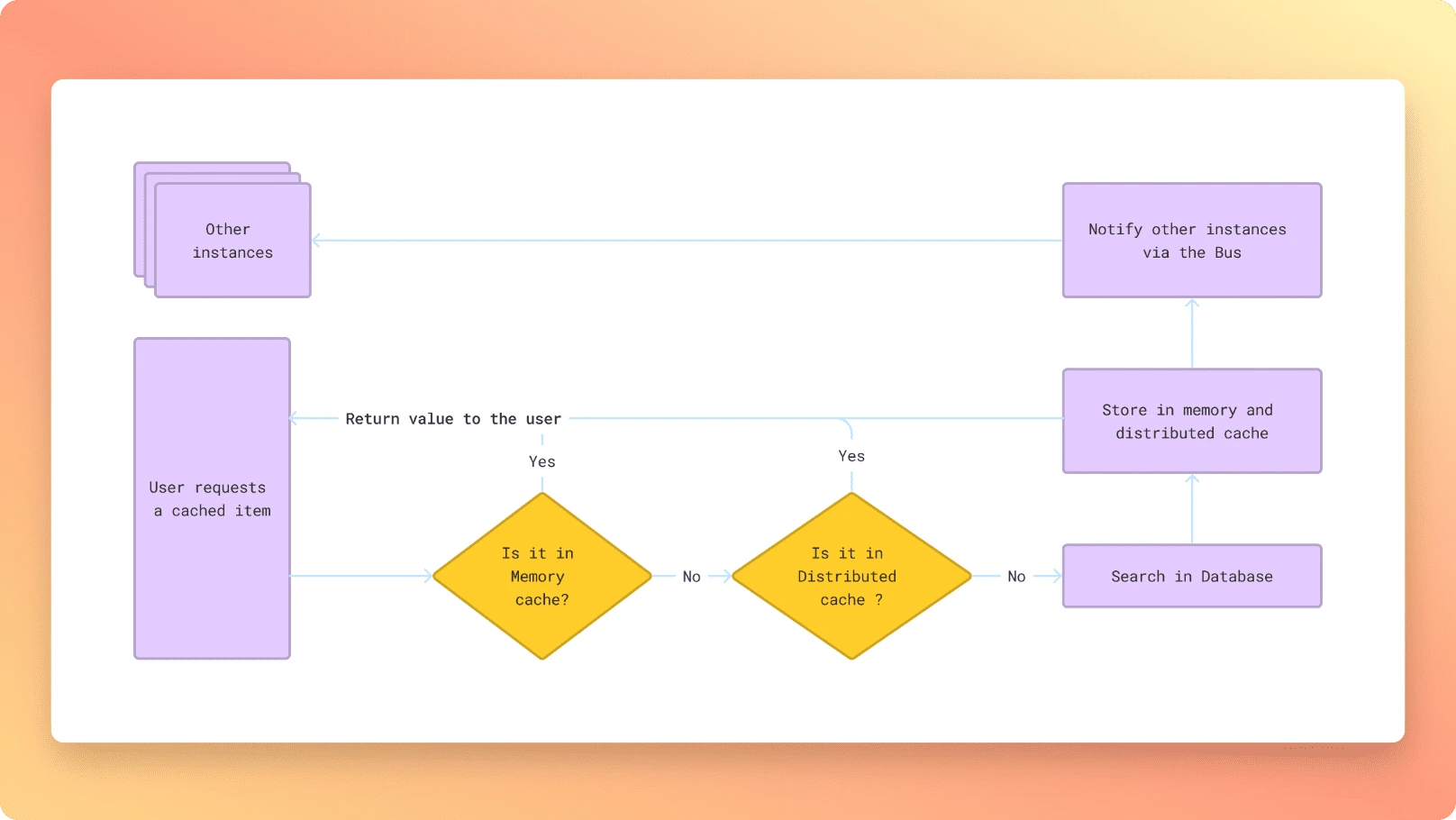
Setup
To create a multi-tier cache with Bentocache, just combine useL1Layer() and useL2Layer() methods when creating your cache instance. You can also use useBus() to add a bus to synchronize the different in-memory caches between the different instances of your application.
If your application is running on a single instance, you don't need to bother with the bus. Just use useL1Layer() and useL2Layer().
import { BentoCache, bentostore } from 'bentocache'
import { memoryDriver } from 'bentocache/drivers/memory'
import { redisDriver,redisBusDriver } from 'bentocache/drivers/redis'
const redisConnection = { host: 'localhost', port: 6379 }
const bento = new BentoCache({
default: 'multitier',
stores: {
multitier: bentostore()
// Your L1 Cache. Here, an in-memory cache with
// a maximum size of 10Mb
.useL1Layer(memoryDriver({ maxSize: '10mb' }))
// Your L2 Cache. Here, a Redis cache
.useL2Layer(redisDriver({ connection: redisConnection }))
// Finally, the bus to synchronize the L1 caches between
// the different instances of your application
.useBus(redisBusDriver({ connection: redisConnection })),
}
})
So here, We have defined a multi-tier cache with :
- L1: An in-memory cache with a maximum size of 10Mb. After that, the LRU algorithm will be used to remove the least recently used items.
- L2: A distributed cache using Redis.
- And a Redis bus to synchronize the in-memory caches between the different instances of your application. The redis bus leverage Redis Pub/Sub system to send messages between instances.
Then, usage is the same as any other cache driver. You can use every method you would use on a normal cache driver. Synchronization between instances, writing to the different caches, etc. everything is handled internally by Bentocache.
Bus
The bus play a crucial role in a multi-tier cache context. It is used to synchronize the different in-memory caches between the different instances of your application.
Let's try to understand why we need it in the first place. We have an applications with 2 instances running in parallel with PM2.
-
N1is callingbento.getOrSet({ key: 'user:1', factory: () => fetchUser(1) }) -
N1is saving the result in in-memory cache + distributed cache. -
After some times,
N2is also callingbento.getOrSet({ key: 'user:1', factory: () => fetchUser(1) }) -
N2check his memory cache, but found nothing. So it fetches data from distributed cache, and saves it in memory cache. -
N1received an update for the user model. So we need to invalidate the cache foruser:1. -
N1invalidates the cache foruser:1in his in-memory cache, and in the distributed cache. Key doesn't exist anymore in both caches. -
However,
N2is still holding the old value in his in-memory cache. he doesn't know that the key has been invalidated. So next time it search foruser:1key, it will find it in his in-memory cache, and will return the old value.
See the problem ? That's why the bus is needed.
How the bus works
The bus is, as the name suggests, just a bus and messaging system. With the redisBusDriver we are leveraging Redis Pub/Sub system to send messages between instances.
Every time a key is invalidated or updated, the instance will notify other ones by sending a message saying "Hey, this key has been invalidated, you should delete it from your cache". Note that we are not sending the new value to other instances, for multiple reasons :
- Maybe the other instance will never need this key. So let's not waste memory space on this instance. It will fetch the value from the distributed cache if needed.
- We also save network bandwidth and not overload the bus with serialized data of the value.
Bus messages are also encoded using a custom binary format instead of plain JSON. This allows us to save a lot of space and bandwidth. Also, JSON.stringify() and JSON.parse() are notoriously slow.
Retry queue strategy
The bus also has a retry queue strategy. If an instance fails to publish a message through the bus, it will be added to a retry queue. As soon as we can publish messages again, we will try to process that queue and send the messages.
This can be configured through the redisBusDriver options as follow :
redisBusDriver({
retryQueue: {
enabled: true,
maxSize: undefined
}
})
maxSize is the maximum number of items that can be stored in the retry queue. If the queue is full, the oldest item will be dropped. If undefined, the queue will have no limit.